
Future Segmentation Prediction Using SimVP and Semi-Supervision
This blog post outlines my research and findings while participating in the final competition hosted in NYU’s Deep Learning class by Prof. Yann Lecun and Prof. Alfredo Canziani.(Spoiler alert, my team won first place!). The problem statement was to predict the segmentation mask of the last frame of a video sequence given the first half of the video. The videos consisted of 3D objects moving about and colliding that follow basic physics principles. We modified the deep learning model, SimVP (Simple Video Predictor), with self-supervision and semi-supervision techniques to predict the segmentation mask of the last frame.
Introduction
Convolutions have been widely acclaimed for their ability to extract spatial features and textures from images. While this works effectively for static images, predicting video frames, which are sequences of images, traditionally relied on sequence models like RNNs and Transformers. However, we built upon the SimVP model, which demonstrates that even convolutions can learn temporal features when applied across the time dimension.

How We Predict the Future
Our model was primarily built on the SimVP model and semi-supervised learning. Here’s a quick rundown of our approach:
Self-Supervision
The model was trained on unlabeled data (13k videos) by defining a pretext task of predicting the next 11 frames from the first 11 frames. Then, we applied this basic SimVP model to the downstream task of predicting the segmentation mask of the 22nd frame.
Independent Segmentation
We also trained a deeplabv3 segmentation model on labeled data. Then we evaluated our self-supervised model by segmenting the predicted 22nd frame against the ground-truth label. While the initial results were promising, there was still room for improvement.
Segmentation using SimVP
Building on the previous steps, we reset the decoder of SimVP with fresh weights, modified the final convolutional layer to output the number of segmentation classes, and trained the modified SimVP on the video training set. This allowed us to achieve more accurate segmentation masks.
Weak semi-supervision
To better leverage our vast unlabeled videos, we generated labels for these videos using the trained deeplabv3 model. This weak-semi supervision step significantly improved our performance.
Data Cleaning
We identified videos with no new objects appearing after the 11th frame and fine-tuned the model on that subset. This significantly increased our Jaccard Score on the validation set.
New Object Suppression (NOS)
We designed a decision tree to clean up predicted masks. The NOS technique corrects the mistakes in model predictions, particularly where the model predicts spurious new objects.
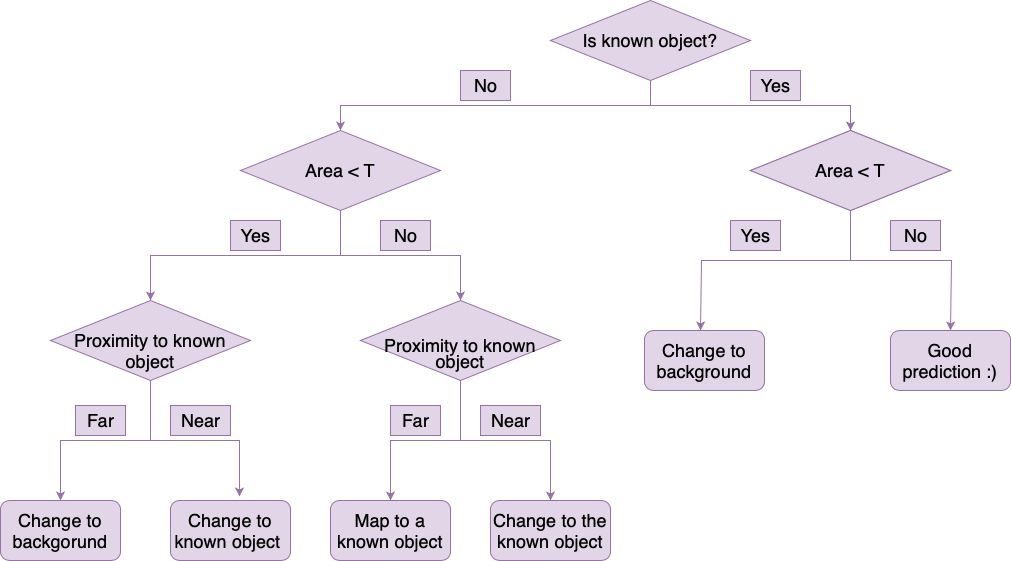
Results
Our model achieved a Jaccard score of 44% on the validation set, demonstrating the potential of SimVP and semi-supervised learning in predicting future segmentation masks in synthetically generated videos. The decision tree heuristics applied improved our Jaccard score from 0.42 to 0.44.
Future Work
In future work, we intend to explore Joint Embedding Predictive Architecture (JEPA) based training where we directly learn in the embedding space through a reconstruction loss. We believe this would enable the model to learn a better energy manifold with the 22 frames in the low energy valley and further enhance its applicability in downstream tasks such as mask segmentation and visual question answering.